Prerequisite
- CNN (Convolutional Neural Network)
https://dev-ryuon.tistory.com/39?category=942362
# 1. Convolution Neural Network (CNN) - Theory
이번 포스트에서는 합성곱(Convolution) 연산을 기반으로 이미지에서 특징을 검출하는데에 적합한 신경망인 CNN에 대해 알아본다. 먼저 CNN의 전체적인 구조에 대해 살펴보자. Input으로 이미지가 들
dev-ryuon.tistory.com
- saturating vs non-saturating
saturate는 사전적으로 '포화하다'라는 의미를 지니고 있다. saturing은 특정 구간에 도달하면 수렴하는 함수를 의미한다. 반대로 non-saturating은 발산하는 함수를 의미한다.
example for saturating)
sigmoid, tanh, ..
example for non-saturating)
ReLU (Rectified Linear Units)
non-saturating을 수식적으로 표현하면 다음과 같다.
$\displaystyle \lim_{z \to +\infty} f(z) = +\infty$ or $\displaystyle \lim_{z \to -\infty} f(z) = +\infty$
- Top-N Error
다중 클래스 분류를 할 경우에 성능 평가 지표(metric)이다. 예를 들어, 1000개의 클래스를 분류하는 분류기가 특정 이미지의 클래스를 분류한 경우, softmax에 의하여 1000개의 각각의 클래스에 속할 확률이 나올 것이다. 이 분류기에 대해 Top-5 Error를 측정한다고 가정해보자.
| Dog | Cat | Horse | Rabbit | Whale | ... |
| 0.3 | 0.1 | 0.05 | 0.02 | 0.01 | ... |
위와 같이 1000개의 클래스에 대해 확률값이 나와있는데, 이중에서 확률이 높은 상위 5개의 클래스만 보고, 이미지의 레이블(실제 정답)이 5개의 클래스에 속해있으면 정답, 아니면 오답으로 처리하여 정확도를 판별하는 것이다.
Dataset
ImageNet 데이터 셋은 1500만장의 고화질 이미지로 구성되어 있다. (22,000개의 카테고리) 해당 논문에서 제안하는 시스템에서는 고정된 차원이 요구되기 때문에 $256 \times 256$으로 이미지를 다운샘플링 하였다.
The Architecture
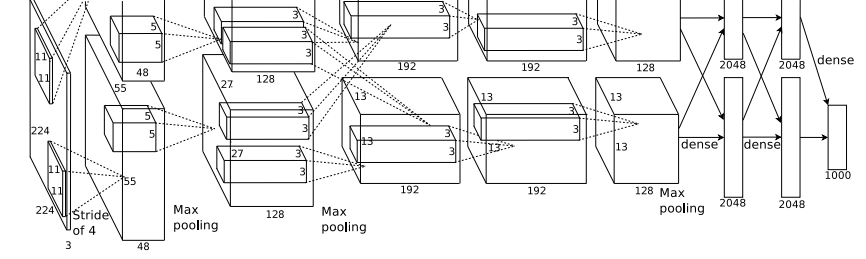
학습이 가능한 레이어는 8개(5 convolutional layers + 3 fully-connected layers)로 구성되어 있다. 학습 파라미터는 총 6000만개이다. 아래에서 본 논문에서 구현한 AlexNet에 필요한 요소들을 소개한다.
ReLU Nonlinearity
$ReLU(x) = max(0, x)$
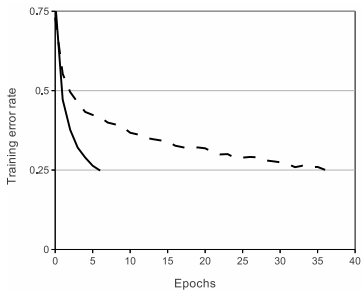
saturating nonlinearity(sigmoid, tanh)과 같은 활성화 함수들은 non-saturating nonlinearity(ReLU)보다 학습 속도가 느리다. 4개의 convolutional layer로 구성된 CNN에서 traditional한 방법(saturating nonlinearity)으로 학습한 선이 점선(dashed line)에 해당하고, non-saturating nonlinearity의 방법이 실선(solid line)에 해당한다. error rate가 25%에 수렴하기 까지 non-saturating 방법이 기존 방법 대비 6배 빠른 속도를 보여주고 있다.
Training on Multiple GPUs
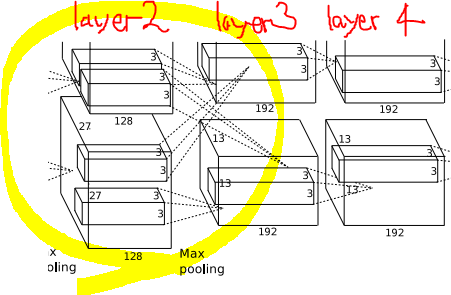
GTX 580은 3GB VRAM밖에 존재하지 않아 네트워크를 전부 적재하기에는 한계가 있다. 그래서 본 논문에서는 GTX 580 GPU 2장을 사용했다. 두 GPU는 특정 레이어에서 서로 소통을 하는데 그 부분은 다음과 같다. layer 3는 layer 2의 모든 kernel map으로부터 입력을 받지만, layer 4는 그렇지 않다.
Local Response Normalization
측면 억제(lateral inbibition) 현상을 방지하기 위한 규제 방법이다. 현재는 BN(Batch Normalization)이 존재하여 별로 사용되는 방법은 아니다. ReLU를 사용하게 되면, 수식상 $max(0, x)$이기 때문에 $x$가 압도적으로 크면, 주변 뉴런에도 영향을 끼친다. 이를 방지하기 위해 일부 인접한 뉴런(커널)들을 정규화 시켜줌으로써 측면 억제 현상을 방지할 수 있다.
$\displaystyle b^i_{x, y} = a^i_{x, y} / (k + \alpha * \sum_{j=max(0, i-n/2)}^{min(N-1, i+n/2)} (a^j_{x, y})^2)^\beta$
| $a^i_{x, y}$ | $n$ | $N$ | $b^i_{x, y}$ |
| $i$ 번째 커널의 $x, y$위치의 값 | 인접 커널의 갯수 | 커널의 전체 갯수 | 정규화된 커널의 값 |
ex) $j = 3, n = 5$
1, 2, 3, 4, 5 번째 커널에 대해 정규화 수행 (자기 자신 j번째 커널을 포함한 n)
Overlapping Pooling
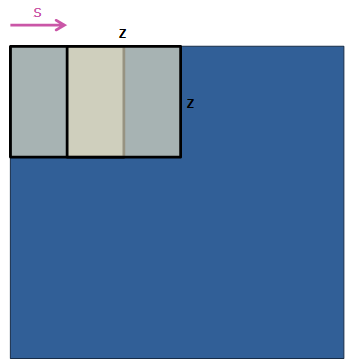
Pooling layer는 같은 커널 맵 내에 존재하는 이웃한 뉴런들의 출력을 요약한다. 더 자세히 설명하자면, $s$ 픽셀 간격으로 $z \times z$ 크기의 이웃들을 요약해서 풀링 유닛의 그리드로 구성되어 있다. 전통적인 방법은 $s = z$지만, Overlapping Pooling은 $s < z$이다. $s = 2, z = 3$으로 설정한 결과, Top-1과 Top-5 error rate가 0.4%, 0.3% 감소하였다. 이는 오버피팅을 감소할 수 있다.
Data Augmentation
오버피팅을 방지하기 가장 쉽고 대중적인 방법은 라벨 보존 변형(label-preserving transformations)을 통한 인위적인 데이터 증강이다. 본 논문에서는 두 가지 형태로 데이터 증강을 수행했다.

첫 번째 방법은 $256 \times 256$ 이미지로부터 $224 \times 224$크기의 5개 구역(이미지의 사각과 중앙)을 추출과 수평 반전(horizontal reflection)을 적용한다. 반전된 구역까지 포함하면 10개의 구역이 나온다.
두 번째 방법은 학습 이미지의 RGB 채널의 강도(intensity) 변경하는 방법이다. 본 논문에서는 RGB 픽셀의 집합에 대해 PCA(Principal Componant Analaysis)를 수행하여 주 성분을 추출한 다음에 모두 더한다.
각각의 RGB 픽셀을 $I_{xy} = [I^R_{xy}, I^G_{xy}, I^B_{xy}]^T$ 라고 한다면, 여기에 $[p_1, p_2, p_3][\alpha_1\lambda_1, \alpha_2\lambda_2, \alpha_3\lambda_3]^T$을 더한다.
(RGB 픽셀에 대한 공분산 행렬을 구한 후, 이를 고유값 분해를 통해 $p_i, \lambda_i$를 구한다. $\alpha_i$는 가우시안 분포(평균 0, 표준편차 0.1)을 따르는 랜덤한 값을 의미한다.)
Dropout
은닉층의 뉴런들의 출력을 0.5 퍼센트 확률로 0으로 세팅해준다. 이 방법을 "dropout" 이라고 부르며, 0.5 퍼센트 확률로 dropout이 된 뉴런은 순전파(forward pass)와 역전파(back propagation)에 영향을 끼칠 수 없다.
참고
- 본 논문
https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
https://stats.stackexchange.com/questions/174295/what-does-the-term-saturating-nonlinearities-mean
What does the term saturating nonlinearities mean?
I was reading the paper ImageNet Classification with Deep Convolutional Neural Networks and in section 3 were they explain the architecture of their Convolutional Neural Network they explain how they
stats.stackexchange.com
https://deepchecks.com/glossary/top-1-error-rate/
What is Top-1 error rate - Deepchecks
The Top-1 error rate is a term used to describe the top-1 accuracy of an algorithm on a classification task.
deepchecks.com
LRN(Local Response Normalization) 이란 무엇인가?(feat. AlexNet)
LRN(Local Response Normalization) LRN(Local Response Normalization)은 현재는 많이 사용되지 않습니다. 그러나 Image Net에서 최초의 CNN우승 모델인 AlexNet에서 사용했으며 작동방식에 대해 알아보도록 하겠..
taeguu.tistory.com
pca_color_augment
PCA Color Augmentation (also called Fancy PCA) alters the intensities of the RGB channels along the natural variations of the images, denoted by the principal components of the pixel colors (Bargoti & Underwood, 2016). It performs Principal Components Anal
aparico.github.io
'논문' 카테고리의 다른 글
| Attention Is All You Need (0) | 2023.06.07 |
|---|---|
| Deep Residual Learning for Image Recognition (0) | 2022.05.15 |
| Going deeper with convolutions (0) | 2022.04.03 |
| Network In Network (0) | 2022.03.28 |